Free Practice Questions for the Snowflake SnowPro Advanced: Architect ARA-C01 Exam (2026 Updated)
At Marks4sure, we are dedicated to providing IT professionals with the most accurate and reliable preparation materials for the Snowflake ARA-C01 exam. To support your certification journey, we have made a selection of our premium 2026 SnowPro Advanced: Architect practice questions and answers available completely free. You can take this practice test as many times as you need. Every question includes a detailed, expertly verified explanation to ensure you fully grasp the core security concepts before test day.
Which technique will efficiently ingest and consume semi-structured data for Snowflake data lake workloads?
A new table and streams are created with the following commands:
CREATE OR REPLACE TABLE LETTERS (ID INT, LETTER STRING) ;
CREATE OR REPLACE STREAM STREAM_1 ON TABLE LETTERS;
CREATE OR REPLACE STREAM STREAM_2 ON TABLE LETTERS APPEND_ONLY = TRUE;
The following operations are processed on the newly created table:
INSERT INTO LETTERS VALUES (1, ' A ' );
INSERT INTO LETTERS VALUES (2, ' B ' );
INSERT INTO LETTERS VALUES (3, ' C ' );
TRUNCATE TABLE LETTERS;
INSERT INTO LETTERS VALUES (4, ' D ' );
INSERT INTO LETTERS VALUES (5, ' E ' );
INSERT INTO LETTERS VALUES (6, ' F ' );
DELETE FROM LETTERS WHERE ID = 6;
What would be the output of the following SQL commands, in order?
SELECT COUNT (*) FROM STREAM_1;
SELECT COUNT (*) FROM STREAM_2;
How can the Snowflake context functions be used to help determine whether a user is authorized to see data that has column-level security enforced? (Select TWO).
The data share exists between a data provider account and a data consumer account. Five tables from the provider account are being shared with the consumer account. The consumer role has been granted the imported privileges privilege.
What will happen to the consumer account if a new table (table_6) is added to the provider schema?
A table for IOT devices that measures water usage is created. The table quickly becomes large and contains more than 2 billion rows.

The general query patterns for the table are:
1. DeviceId, lOT_timestamp and Customerld are frequently used in the filter predicate for the select statement
2. The columns City and DeviceManuf acturer are often retrieved
3. There is often a count on Uniqueld
Which field(s) should be used for the clustering key?
A media company needs a data pipeline that will ingest customer review data into a Snowflake table, and apply some transformations. The company also needs to use Amazon Comprehend to do sentiment analysis and make the de-identified final data set available publicly for advertising companies who use different cloud providers in different regions.
The data pipeline needs to run continuously and efficiently as new records arrive in the object storage leveraging event notifications. Also, the operational complexity, maintenance of the infrastructure, including platform upgrades and security, and the development effort should be minimal.
Which design will meet these requirements?
An Architect entered the following commands in sequence:

USER1 cannot find the table.
Which of the following commands does the Architect need to run for USER1 to find the tables using the Principle of Least Privilege? (Choose two.)
A company has a Snowflake account named ACCOUNTA in AWS us-east-1 region. The company stores its marketing data in a Snowflake database named MARKET_DB. One of the company’s business partners has an account named PARTNERB in Azure East US 2 region. For marketing purposes the company has agreed to share the database MARKET_DB with the partner account.
Which of the following steps MUST be performed for the account PARTNERB to consume data from the MARKET_DB database?
A company’s client application supports multiple authentication methods, and is using Okta.
What is the best practice recommendation for the order of priority when applications authenticate to Snowflake?
Assuming all Snowflake accounts are using an Enterprise edition or higher, in which development and testing scenarios would be copying of data be required, and zero-copy cloning not be suitable? (Select TWO).
What is a characteristic of loading data into Snowflake using the Snowflake Connector for Kafka?
An Architect needs to design a solution for building environments for development, test, and pre-production, all located in a single Snowflake account. The environments should be based on production data.
Which solution would be MOST cost-effective and performant?
Which of the following ingestion methods can be used to load near real-time data by using the messaging services provided by a cloud provider?
An Architect is troubleshooting a query with poor performance using the QUERY function. The Architect observes that the COMPILATION_TIME Is greater than the EXECUTION_TIME.
What is the reason for this?
An Architect is designing partitioned external tables for a Snowflake data lake. The data lake size may grow over time, and partition definitions may need to change in the future.
How can these requirements be met?
A media company needs a data pipeline that will ingest customer review data into a Snowflake table, and apply some transformations. The company also needs to use Amazon Comprehend to do sentiment analysis and make the de-identified final data set available publicly for advertising companies who use different cloud providers in different regions.
The data pipeline needs to run continuously ang efficiently as new records arrive in the object storage leveraging event notifications. Also, the operational complexity, maintenance of the infrastructure, including platform upgrades and security, and the development effort should be minimal.
Which design will meet these requirements?
Company A would like to share data in Snowflake with Company B. Company B is not on the same cloud platform as Company A.
What is required to allow data sharing between these two companies?
How is the change of local time due to daylight savings time handled in Snowflake tasks? (Choose two.)
Why does a conditional multi-table insert option support the Data Vault data model?
A healthcare company wants to share data with a medical institute. The institute is running a Standard edition of Snowflake; the healthcare company is running a Business Critical edition.
How can this data be shared?
When activating Tri-Secret Secure in a hierarchical encryption model in a Snowflake account, at what level is the customer-managed key used?
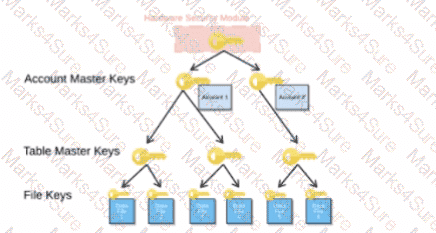
A global company needs to securely share its sales and Inventory data with a vendor using a Snowflake account.
The company has its Snowflake account In the AWS eu-west 2 Europe (London) region. The vendor ' s Snowflake account Is on the Azure platform in the West Europe region. How should the company ' s Architect configure the data share?
How can an Architect enable optimal clustering to enhance performance for different access paths on a given table?
An Architect is using an event table associated with a Sales database (sales_db) to track logging and tracing of procedures and functions. The event table is also used to refresh dynamic tables.
A stored procedure causing issues resides in the Marketing database (marketing_db). Both databases are in the same Snowflake account. The Marketing database is not associated with a specific event table.
How can the Architect investigate the issue?
What is the MOST efficient way to design an environment where data retention is not considered critical, and customization needs are to be kept to a minimum?
Which feature provides the capability to define an alternate cluster key for a table with an existing cluster key?
The following chart represents the performance of a virtual warehouse over time:
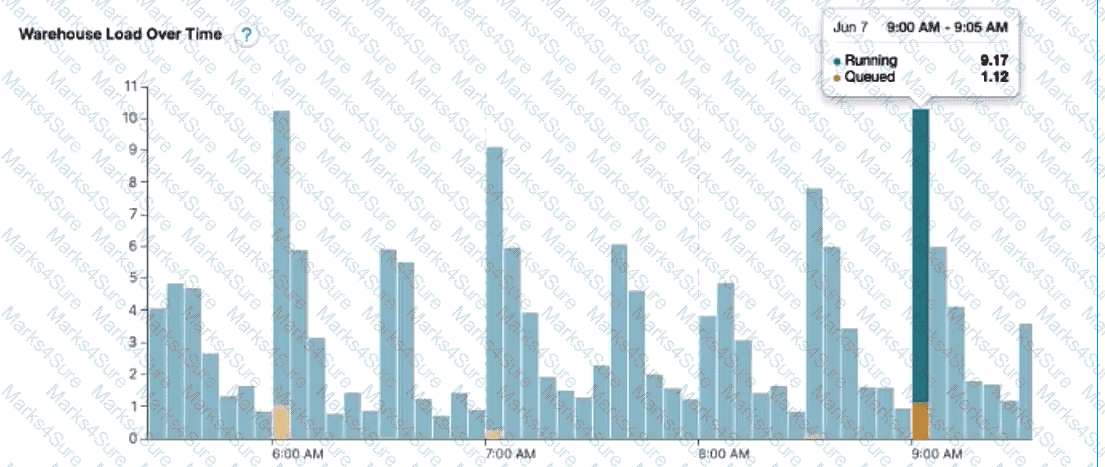
A Data Engineer notices that the warehouse is queueing queries. The warehouse is sizeX-Small, theminimum and maximum cluster counts are set to 1, thescaling policy is set to standard, andauto-suspend is set to 10 minutes.
How can the performance be improved?
The following table exists in the production database:
A regulatory requirement states that the company must mask the username for events that are older than six months based on the current date when the data is queried.
How can the requirement be met without duplicating the event data and making sure it is applied when creating views using the table or cloning the table?
Which steps are recommended best practices for prioritizing cluster keys in Snowflake? (Choose two.)
An Architect needs to improve the performance of reports that pull data from multiple Snowflake tables, join, and then aggregate the data. Users access the reports using several dashboards. There are performance issues on Monday mornings between 9:00am-11:00am when many users check the sales reports.
The size of the group has increased from 4 to 8 users. Waiting times to refresh the dashboards has increased significantly. Currently this workload is being served by a virtual warehouse with the following parameters:
AUTO-RESUME = TRUE AUTO_SUSPEND = 60 SIZE = Medium
What is the MOST cost-effective way to increase the availability of the reports?
An Architect is using SnowCD to investigate a connectivity issue.
Which system function will provide a list of endpoints that the network must be able to access to use a specific Snowflake account, leveraging private connectivity?
An Architect is troubleshooting a query with poor performance using the QUERY_HIST0RY function. The Architect observes that the COMPILATIONJHME is greater than the EXECUTIONJTIME.
What is the reason for this?
What actions are permitted when using the Snowflake SQL REST API? (Select TWO).
An Architect clones a database and all of its objects, including tasks. After the cloning, the tasks stop running.
Why is this occurring?
A Snowflake Architect Is working with Data Modelers and Table Designers to draft an ELT framework specifically for data loading using Snowpipe. The Table Designers will add a timestamp column that Inserts the current tlmestamp as the default value as records are loaded into a table. The Intent is to capture the time when each record gets loaded into the table; however, when tested the timestamps are earlier than the loae_take column values returned by the copy_history function or the Copy_HISTORY view (Account Usage).
Why Is this occurring?
Role A has the following permissions:
. USAGE on db1
. USAGE and CREATE VIEW on schemal in db1
. SELECT on tablel in schemal
Role B has the following permissions:
. USAGE on db2
. USAGE and CREATE VIEW on schema2 in db2
. SELECT on table2 in schema2
A user has Role A set as the primary role and Role B as a secondary role.
What command will fail for this user?
An Architect is designing a file ingestion recovery solution. The project will use an internal named stage for file storage. Currently, in the case of an ingestion failure, the Operations team must manually download the failed file and check for errors.
Which downloading method should the Architect recommend that requires the LEAST amount of operational overhead?
Which SQL ALTER command will MAXIMIZE memory and compute resources for a Snowpark stored procedure when executed on the snowpark_opt_wh warehouse?
When using the COPY INTO
command with the CSV file format, how does the MATCH_BY_COLUMN_NAME parameter behave?
A Snowflake Architect created a new data share and would like to verify that only specific records in secure views are visible within the data share by the consumers.
What is the recommended way to validate data accessibility by the consumers?
A company is trying to Ingest 10 TB of CSV data into a Snowflake table using Snowpipe as part of Its migration from a legacy database platform. The records need to be ingested in the MOST performant and cost-effective way.
How can these requirements be met?
Which security, governance, and data protection features require, at a MINIMUM, the Business Critical edition of Snowflake? (Choose two.)
A company needs to have the following features available in its Snowflake account:
1. Support for Multi-Factor Authentication (MFA)
2. A minimum of 2 months of Time Travel availability
3. Database replication in between different regions
4. Native support for JDBC and ODBC
5. Customer-managed encryption keys using Tri-Secret Secure
6. Support for Payment Card Industry Data Security Standards (PCI DSS)
In order to provide all the listed services, what is the MINIMUM Snowflake edition that should be selected during account creation?
A company is designing a process for importing a large amount of loT JSON data from cloud storage into Snowflake. New sets of loT data get generated and uploaded approximately every 5 minutes.
Once the loT data is in Snowflake, the company needs up-to-date information from an external vendor to join to the data. This data is then presented to users through a dashboard that shows different levels of aggregation. The external vendor is a Snowflake customer.
What solution will MINIMIZE complexity and MAXIMIZE performance?
What integration object should be used to place restrictions on where data may be exported?
An Architect needs to design a Snowflake account and database strategy to store and analyze large amounts of structured and semi-structured data. There are many business units and departments within the company. The requirements are scalability, security, and cost efficiency.
What design should be used?
An Architect needs to allow a user to create a database from an inbound share.
To meet this requirement, the user’s role must have which privileges? (Choose two.)
A Snowflake Architect is designing a multi-tenant application strategy for an organization in the Snowflake Data Cloud and is considering using an Account Per Tenant strategy.
Which requirements will be addressed with this approach? (Choose two.)
The Data Engineering team at a large manufacturing company needs to engineer data coming from many sources to support a wide variety of use cases and data consumer requirements which include:
1) Finance and Vendor Management team members who require reporting and visualization
2) Data Science team members who require access to raw data for ML model development
3) Sales team members who require engineered and protected data for data monetization
What Snowflake data modeling approaches will meet these requirements? (Choose two.)
PDF + Testing Engine

Testing Engine
PDF (Q&A)
