Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Databricks Certified Associate Developer for Apache Spark 3.5 – Python Questions and Answers
Given a DataFrame df that has 10 partitions, after running the code:
result = df.coalesce(20)
How many partitions will the result DataFrame have?
A Spark developer wants to improve the performance of an existing PySpark UDF that runs a hash function that is not available in the standard Spark functions library. The existing UDF code is:

import hashlib
import pyspark.sql.functions as sf
from pyspark.sql.types import StringType
def shake_256(raw):
return hashlib.shake_256(raw.encode()).hexdigest(20)
shake_256_udf = sf.udf(shake_256, StringType())
The developer wants to replace this existing UDF with a Pandas UDF to improve performance. The developer changes the definition of shake_256_udf to this: CopyEdit
shake_256_udf = sf.pandas_udf(shake_256, StringType())
However, the developer receives the error:
What should the signature of the shake_256() function be changed to in order to fix this error?
43 of 55.
An organization has been running a Spark application in production and is considering disabling the Spark History Server to reduce resource usage.
What will be the impact of disabling the Spark History Server in production?
A data engineer wants to create an external table from a JSON file located at /data/input.json with the following requirements:
Create an external table named users
Automatically infer schema
Merge records with differing schemas
Which code snippet should the engineer use?
Options:
An engineer notices a significant increase in the job execution time during the execution of a Spark job. After some investigation, the engineer decides to check the logs produced by the Executors.
How should the engineer retrieve the Executor logs to diagnose performance issues in the Spark application?
A data engineer is building an Apache Spark™ Structured Streaming application to process a stream of JSON events in real time. The engineer wants the application to be fault-tolerant and resume processing from the last successfully processed record in case of a failure. To achieve this, the data engineer decides to implement checkpoints.
Which code snippet should the data engineer use?
25 of 55.
A Data Analyst is working on employees_df and needs to add a new column where a 10% tax is calculated on the salary.
Additionally, the DataFrame contains the column age, which is not needed.
Which code fragment adds the tax column and removes the age column?
30 of 55.
A data engineer is working on a num_df DataFrame and has a Python UDF defined as:
def cube_func(val):
return val * val * val
Which code fragment registers and uses this UDF as a Spark SQL function to work with the DataFrame num_df?
What is the risk associated with this operation when converting a large Pandas API on Spark DataFrame back to a Pandas DataFrame?
A data engineer is building a Structured Streaming pipeline and wants the pipeline to recover from failures or intentional shutdowns by continuing where the pipeline left off.
How can this be achieved?
9 of 55.
Given the code fragment:
import pyspark.pandas as ps
pdf = ps.DataFrame(data)
Which method is used to convert a Pandas API on Spark DataFrame (pyspark.pandas.DataFrame) into a standard PySpark DataFrame (pyspark.sql.DataFrame)?
A developer is running Spark SQL queries and notices underutilization of resources. Executors are idle, and the number of tasks per stage is low.
What should the developer do to improve cluster utilization?
40 of 55.
A developer wants to refactor older Spark code to take advantage of built-in functions introduced in Spark 3.5.
The original code:
from pyspark.sql import functions as F
min_price = 110.50
result_df = prices_df.filter(F.col( " price " ) > min_price).agg(F.count( " * " ))
Which code block should the developer use to refactor the code?
Given the code:

df = spark.read.csv( " large_dataset.csv " )
filtered_df = df. filter (col( " error_column " ).contains( " error " ))
mapped_df = filtered_df.select(split(col( " timestamp " ), " " ).getItem( 0 ).alias( " date " ), lit( 1 ).alias( " count " ))
reduced_df = mapped_df.groupBy( " date " ). sum ( " count " )
reduced_df.count()
reduced_df.show()
At which point will Spark actually begin processing the data?
A DataFrame df has columns name , age , and salary . The developer needs to sort the DataFrame by age in ascending order and salary in descending order.
Which code snippet meets the requirement of the developer?
41 of 55.
A data engineer is working on the DataFrame df1 and wants the Name with the highest count to appear first (descending order by count), followed by the next highest, and so on.
The DataFrame has columns:
id | Name | count | timestamp
---------------------------------
1 | USA | 10
2 | India | 20
3 | England | 50
4 | India | 50
5 | France | 20
6 | India | 10
7 | USA | 30
8 | USA | 40
Which code fragment should the engineer use to sort the data in the Name and count columns?
A data engineer wants to create a Streaming DataFrame that reads from a Kafka topic called feed.

Which code fragment should be inserted in line 5 to meet the requirement?
Code context:
spark \
.readStream \
. format ( " kafka " ) \
.option( " kafka.bootstrap.servers " , " host1:port1,host2:port2 " ) \
.[LINE 5 ] \
.load()
Options:
A Data Analyst needs to retrieve employees with 5 or more years of tenure.
Which code snippet filters and shows the list?
A data engineer writes the following code to join two DataFrames df1 and df2 :
df1 = spark.read.csv( " sales_data.csv " ) # ~10 GB
df2 = spark.read.csv( " product_data.csv " ) # ~8 MB
result = df1.join(df2, df1.product_id == df2.product_id)

Which join strategy will Spark use?
24 of 55.
Which code should be used to display the schema of the Parquet file stored in the location events.parquet?
A data scientist is working on a project that requires processing large amounts of structured data, performing SQL queries, and applying machine learning algorithms. The data scientist is considering using Apache Spark for this task.
Which combination of Apache Spark modules should the data scientist use in this scenario?
Options:
A data engineer replaces the exact percentile() function with approx_percentile() to improve performance, but the results are drifting too far from expected values.
Which change should be made to solve the issue?
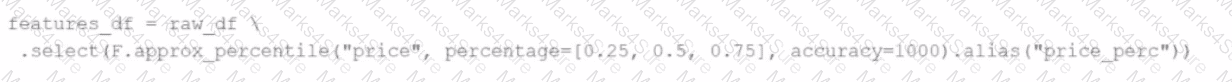
8 of 55.
A data scientist at a large e-commerce company needs to process and analyze 2 TB of daily customer transaction data. The company wants to implement real-time fraud detection and personalized product recommendations .
Currently, the company uses a traditional relational database system, which struggles with the increasing data volume and velocity.
Which feature of Apache Spark effectively addresses this challenge?
What is the relationship between jobs, stages, and tasks during execution in Apache Spark?
Options:
35 of 55.
A data engineer is building a Structured Streaming pipeline and wants it to recover from failures or intentional shutdowns by continuing where it left off.
How can this be achieved?
A developer is working with a pandas DataFrame containing user behavior data from a web application.
Which approach should be used for executing a groupBy operation in parallel across all workers in Apache Spark 3.5?
A)
Use the applylnPandas API
B)

C)

D)

A data scientist wants each record in the DataFrame to contain:
The first attempt at the code does read the text files but each record contains a single line. This code is shown below:

The entire contents of a file
The full file path
The issue: reading line-by-line rather than full text per file.
Code:
corpus = spark.read.text( " /datasets/raw_txt/* " ) \
.select( ' * ' , ' _metadata.file_path ' )
Which change will ensure one record per file?
Options:
17 of 55.
A data engineer has noticed that upgrading the Spark version in their applications from Spark 3.0 to Spark 3.5 has improved the runtime of some scheduled Spark applications.
Looking further, the data engineer realizes that Adaptive Query Execution (AQE) is now enabled.
Which operation should AQE be implementing to automatically improve the Spark application performance?
42 of 55.
A developer needs to write the output of a complex chain of Spark transformations to a Parquet table called events.liveLatest.
Consumers of this table query it frequently with filters on both year and month of the event_ts column (a timestamp).
The current code:
from pyspark.sql import functions as F
final = df.withColumn( " event_year " , F.year( " event_ts " )) \
.withColumn( " event_month " , F.month( " event_ts " )) \
.bucketBy(42, [ " event_year " , " event_month " ]) \
.saveAsTable( " events.liveLatest " )
However, consumers report poor query performance.
Which change will enable efficient querying by year and month?
29 of 55.
A Spark application is experiencing performance issues in client mode due to the driver being resource-constrained.
How should this issue be resolved?
Given the code fragment:

import pyspark.pandas as ps
psdf = ps.DataFrame({ ' col1 ' : [1, 2], ' col2 ' : [3, 4]})
Which method is used to convert a Pandas API on Spark DataFrame ( pyspark.pandas.DataFrame ) into a standard PySpark DataFrame ( pyspark.sql.DataFrame )?
An MLOps engineer is building a Pandas UDF that applies a language model that translates English strings into Spanish. The initial code is loading the model on every call to the UDF, which is hurting the performance of the data pipeline.
The initial code is:

def in_spanish_inner(df: pd.Series) - > pd.Series:
model = get_translation_model(target_lang= ' es ' )
return df.apply(model)
in_spanish = sf.pandas_udf(in_spanish_inner, StringType())
How can the MLOps engineer change this code to reduce how many times the language model is loaded?
13 of 55.
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which looks like this:
region_id
region_name
10
North
12
East
14
West
The resulting Python dictionary must contain a mapping of region_id to region_name, containing the smallest 3 region_id values.
Which code fragment meets the requirements?
49 of 55.
In the code block below, aggDF contains aggregations on a streaming DataFrame:
aggDF.writeStream \
.format( " console " ) \
.outputMode( " ??? " ) \
.start()
Which output mode at line 3 ensures that the entire result table is written to the console during each trigger execution?
A Spark engineer must select an appropriate deployment mode for the Spark jobs.
What is the benefit of using cluster mode in Apache Spark™?
In the code block below, aggDF contains aggregations on a streaming DataFrame:

Which output mode at line 3 ensures that the entire result table is written to the console during each trigger execution?
A data engineer needs to write a DataFrame df to a Parquet file, partitioned by the column country , and overwrite any existing data at the destination path.
Which code should the data engineer use to accomplish this task in Apache Spark?
PDF + Testing Engine

Testing Engine
PDF (Q&A)
