Free Practice Questions for the Snowflake SnowPro Advanced DEA-C01 Exam (2026 Updated)
At Marks4sure, we are dedicated to providing IT professionals with the most accurate and reliable preparation materials for the Snowflake DEA-C01 exam. To support your certification journey, we have made a selection of our premium 2026 SnowPro Advanced practice questions and answers available completely free. You can take this practice test as many times as you need. Every question includes a detailed, expertly verified explanation to ensure you fully grasp the core security concepts before test day.
A company built a sales reporting system with Python, connecting to Snowflake using the Python Connector. Based on the user's selections, the system generates the SQL queries needed to fetch the data for the report First it gets the customers that meet the given query parameters (on average 1000 customer records for each report run) and then it loops the customer records sequentially Inside that loop it runs the generated SQL clause for the current customer to get the detailed data for that customer number from the sales data table
When the Data Engineer tested the individual SQL clauses they were fast enough (1 second to get the customers 0 5 second to get the sales data for one customer) but the total runtime of the report is too long
How can this situation be improved?
Database XYZ has the data_retention_time_in_days parameter set to 7 days and table xyz.public.ABC has the data_retention_time_in_days set to 10 days.
A Developer accidentally dropped the database containing this single table 8 days ago and just discovered the mistake.
How can the table be recovered?
A Data Engineer is building a pipeline to transform a 1 TD tab e by joining it with supplemental tables The Engineer is applying filters and several aggregations leveraging Common Table Expressions (CTEs) using a size Medium virtual warehouse in a single query in Snowflake.
After checking the Query Profile, what is the recommended approach to MAXIMIZE performance of this query if the Profile shows data spillage?
When would a Data engineer use table with the flatten function instead of the lateral flatten combination?
A secure function returns data coming through an inbound share
What will happen if a Data Engineer tries to assign usage privileges on this function to an outbound share?
While running an external function, me following error message is received:
Error: function received the wrong number of rows
What is causing this to occur?
Which system role is recommended for a custom role hierarchy to be ultimately assigned to?
Which methods will trigger an action that will evaluate a DataFrame? (Select TWO)
A Data Engineer needs to load JSON output from some software into Snowflake using Snowpipe.
Which recommendations apply to this scenario? (Select THREE)
A Data Engineer needs to know the details regarding the micro-partition layout for a table named invoice using a built-in function.
Which query will provide this information?
Given the table sales which has a clustering key of column CLOSED_DATE which table function will return the average clustering depth for the SALES_REPRESENTATIVE column for the North American region?
A)

B)
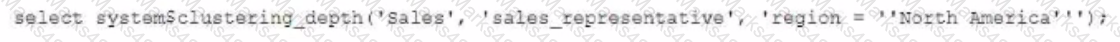
C)

D)

A table is loaded using Snowpipe and truncated afterwards Later, a Data Engineer finds that the table needs to be reloaded but the metadata of the pipe will not allow the same files to be loaded again.
How can this issue be solved using the LEAST amount of operational overhead?
A new customer table is created by a data pipeline in a Snowflake schema where MANAGED ACCESS enabled.
…. Can gran access to the CUSTOMER table? (Select THREE.)
The following chart represents the performance of a virtual warehouse over time:

A Data Engineer notices that the warehouse is queueing queries The warehouse is size X-Small the minimum and maximum cluster counts are set to 1 the scaling policy is set to i and auto-suspend is set to 10 minutes.
How can the performance be improved?
PDF + Testing Engine

Testing Engine
PDF (Q&A)
