Free Practice Questions for the Microsoft Azure DP-100 Exam (2026 Updated)
At Marks4sure, we are dedicated to providing IT professionals with the most accurate and reliable preparation materials for the Microsoft DP-100 exam. To support your certification journey, we have made a selection of our premium 2026 Microsoft Azure practice questions and answers available completely free. You can take this practice test as many times as you need. Every question includes a detailed, expertly verified explanation to ensure you fully grasp the core security concepts before test day.
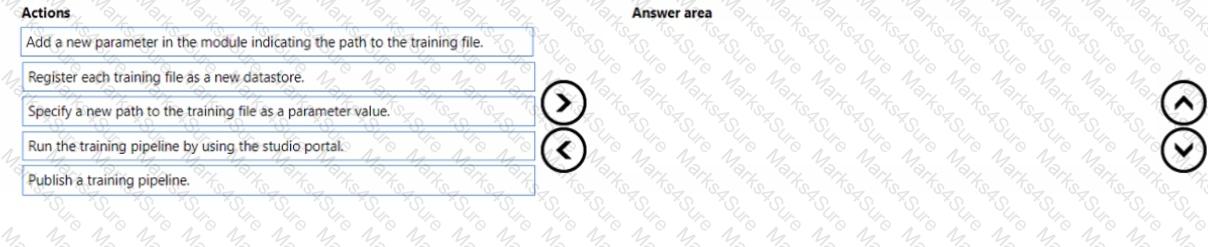
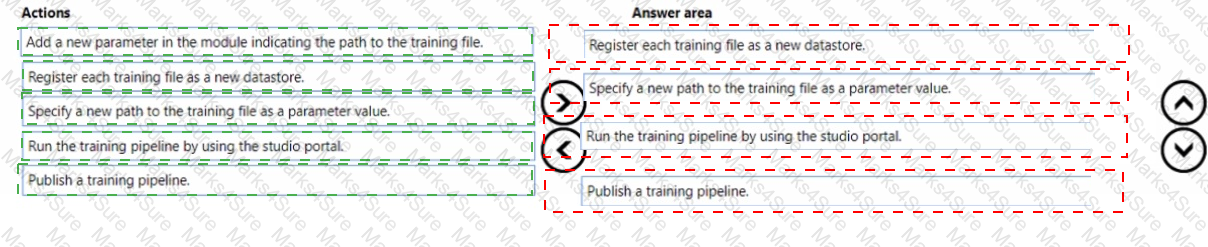
You use a training pipeline in the Azure Machine Learning designer. You register a datastore named ds1. The datastore contains multiple training data files. You use the Import Data module with the configured datastore.
You need to retrain a model on a different set of data files.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
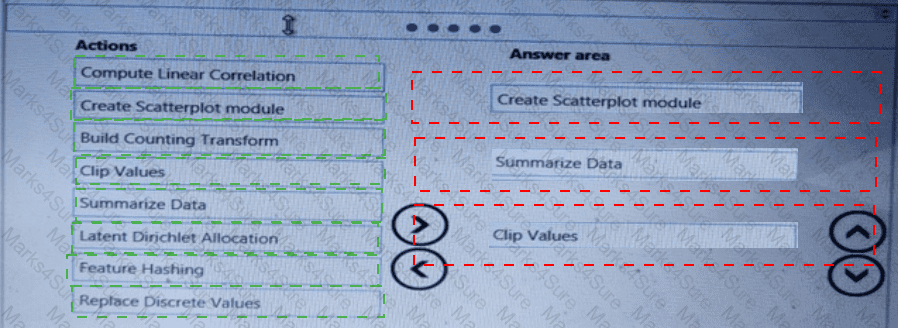
You are analyzing a raw dataset that requires cleaning.
You must perform transformations and manipulations by using Azure Machine Learning Studio.
You need to identify the correct modules to perform the transformations.
Which modules should you choose? To answer, drag the appropriate modules to the correct scenarios. Each module may be used once, more than once, or not at all.
You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.



You manage an Azure Machine Learning workspace. The Pylhon scrip! named scriptpy reads an argument named training_data. The trainlng.data argument specifies the path to the training data in a file named datasetl.csv.
You plan to run the scriptpy Python script as a command job that trains a machine learning model.
You need to provide the command to pass the path for the datasct as a parameter value when you submit the script as a training job.
Solution: python train.py --training_data training_data
Does the solution meet the goal?
You arc creating a new experiment in Azure Machine Learning Studio. You have a small dataset that has missing values in many columns. The data does not require the application of predictors for each column. You plan to use the Clean Missing Data module to handle the missing data.
You need to select a data cleaning method.
Which method should you use?
You create an Azure Machine Learning workspace and an Azure Synapse Analytics workspace with a Spark pool. The workspaces are contained within the same Azure subscription.
You must manage the Synapse Spark pool from the Azure Machine Learning workspace.
You need to attach the Synapse Spark pool in Azure Machine Learning by usinq the Python SDK v2.
Which three actions should you perform in sequence? To answer move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


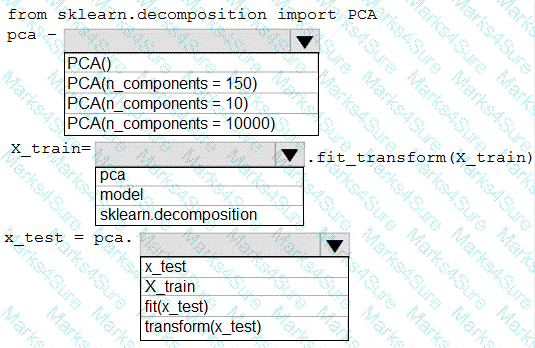
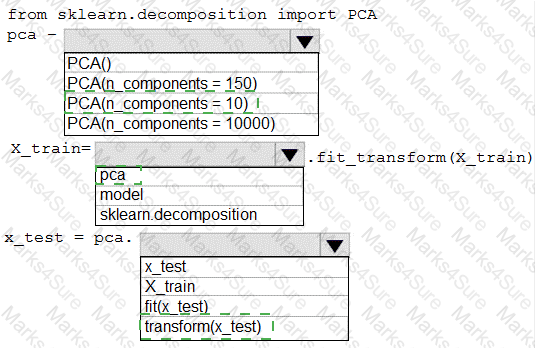
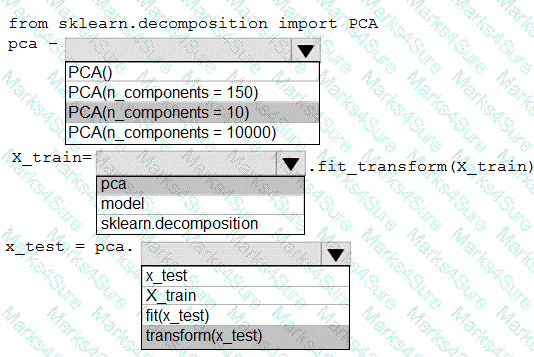
You have a dataset created for multiclass classification tasks that contains a normalized numerical feature set with 10,000 data points and 150 features.
You use 75 percent of the data points for training and 25 percent for testing. You are using the scikit-learn machine learning library in Python. You use X to denote the feature set and Y to denote class labels.
You create the following Python data frames:
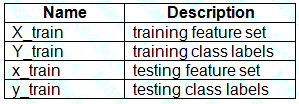
You need to apply the Principal Component Analysis (PCA) method to reduce the dimensionality of the feature set to 10 features in both training and testing sets.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You use an Azure Machine Learning workspace. Azure Data Factor/ pipeline, and a dataset monitor that runs en a schedule to detect data drift.
You need to Implement an automated workflow to trigger when the dataset monitor detects data drift and launch the Azure Data Factory pipeline to update the dataset. The solution must minimize the effort to configure the workflow.
How should you configure the workflow? To answer select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You plan to run a Python script as an Azure Machine Learning experiment.
The script contains the following code:
import os, argparse, glob
from azureml.core import Run
parser = argparse.ArgumentParser()
parser.add_argument( ' --input-data ' ,
type=str, dest= ' data_folder ' )
args = parser.parse_args()
data_path = args.data_folder
file_paths = glob.glob(data_path + " /*.jpg " )
You must specify a file dataset as an input to the script. The dataset consists of multiple large image files and must be streamed directly from its source.
You need to write code to define a ScriptRunConfig object for the experiment and pass the ds dataset as an argument.
Which code segment should you use?
You are performing feature engineering on a dataset.
You must add a feature named CityName and populate the column value with the text London.
You need to add the new feature to the dataset.
Which Azure Machine Learning Studio module should you use?
You use an Azure Machine Learning workspace.
You create the following Python code:

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.



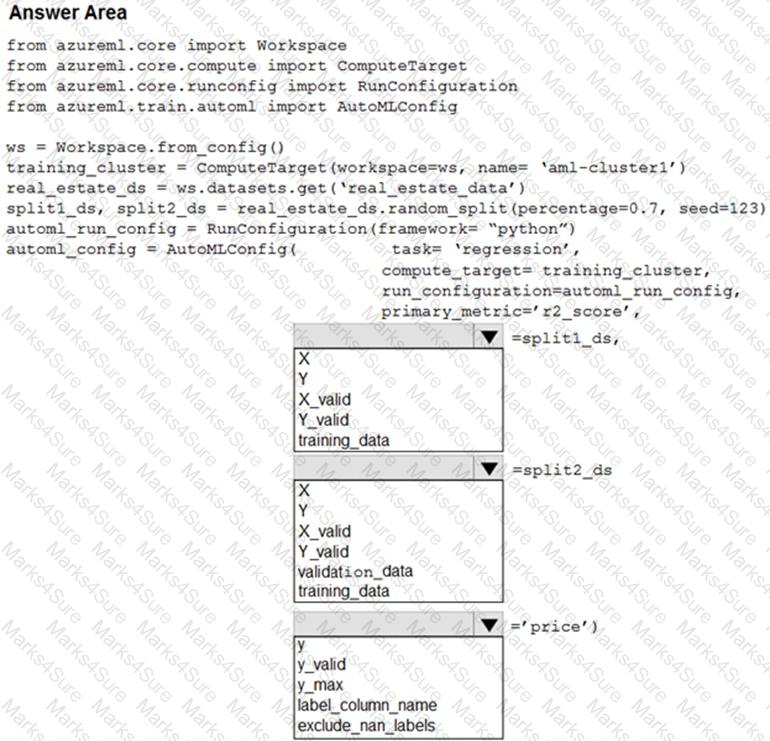
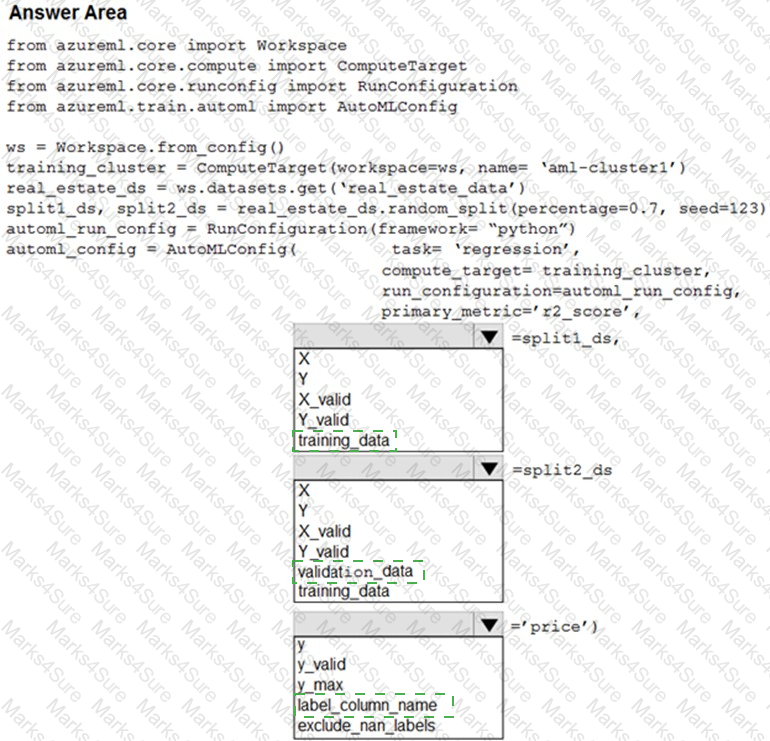
Your Azure Machine Learning workspace has a dataset named real_estate_data. A sample of the data in the dataset follows.

You want to use automated machine learning to find the best regression model for predicting the price column.
You need to configure an automated machine learning experiment using the Azure Machine Learning SDK.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You use the Azure Machine Learning SDK v2 for Python and notebooks to train a model. You use Python code to create a compute target an environment and a training script You need to prepare information to submit a training job. Which class should you use?
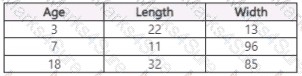
You use Azure Machine Learning Designer to load the following datasets into an experiment:
Data set 1
Dataset 2
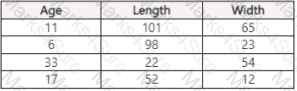
You need to create a dataset that has the same columns and header row as the input datasets and contains all rows from both input datasets.
Solution: Use the Apply Transformation component.
Does the solution meet the goal?
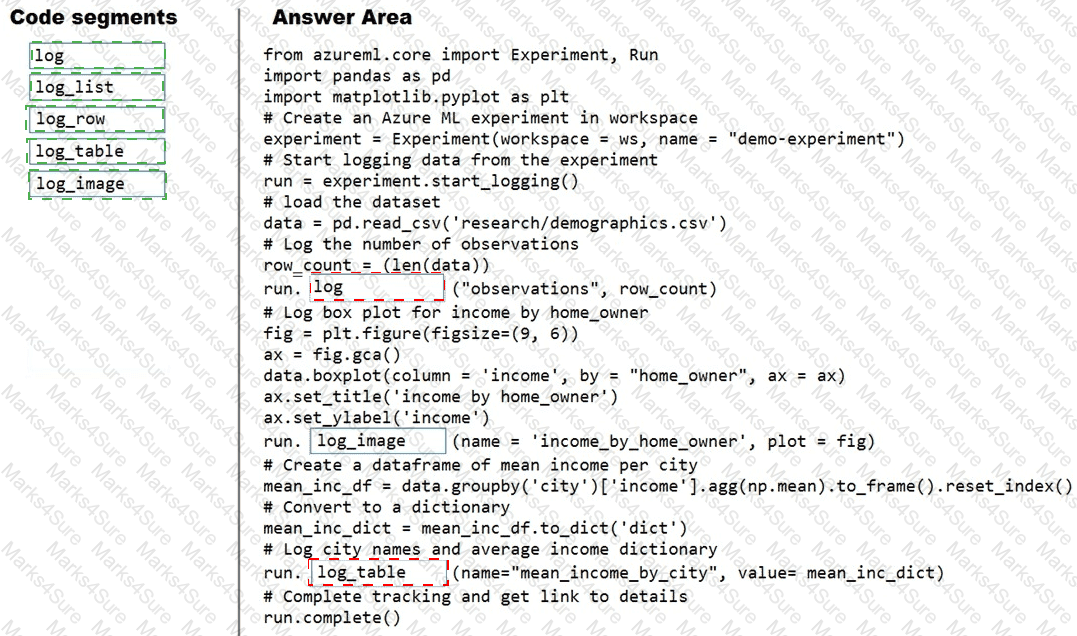
You plan to explore demographic data for home ownership in various cities. The data is in a CSV file with the following format:
age,city,income,home_owner
21,Chicago,50000,0
35,Seattle,120000,1
23,Seattle,65000,0
45,Seattle,130000,1
18,Chicago,48000,0
You need to run an experiment in your Azure Machine Learning workspace to explore the data and log the results. The experiment must log the following information:
the number of observations in the dataset
a box plot of income by home_owner
a dictionary containing the city names and the average income for each city
You need to use the appropriate logging methods of the experiment’s run object to log the required information.
How should you complete the code? To answer, drag the appropriate code segments to the correct locations. Each code segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

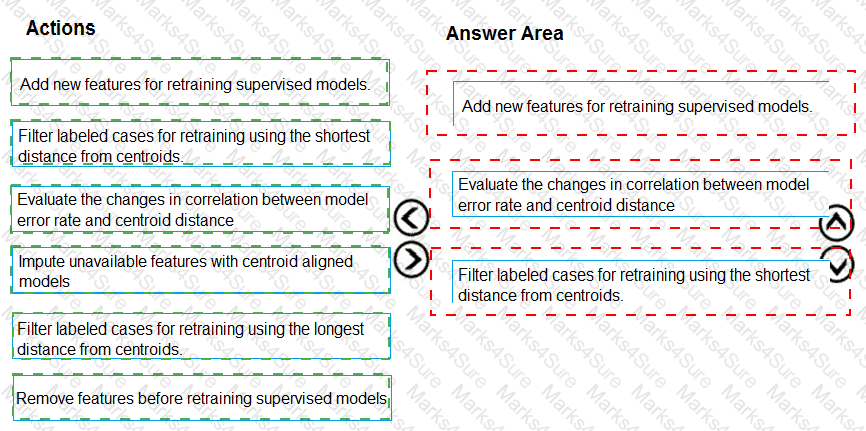

You need to select an environment that will meet the business and data requirements.
Which environment should you use?
You need to resolve the local machine learning pipeline performance issue. What should you do?
You need to define a modeling strategy for ad response.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
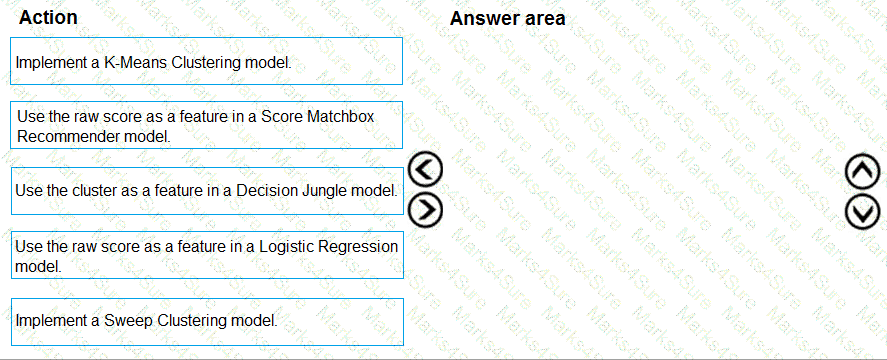
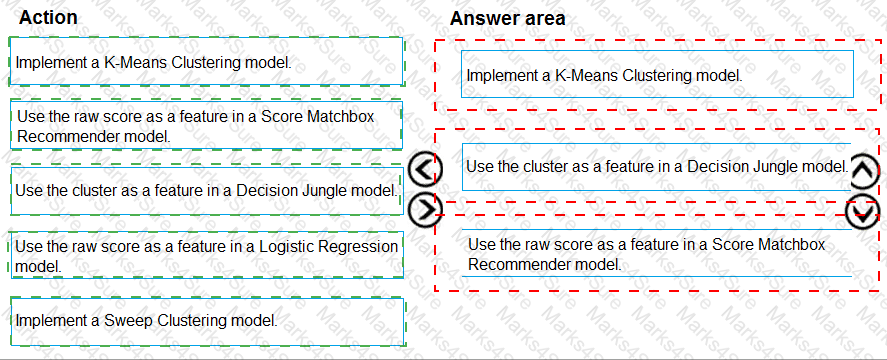

You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
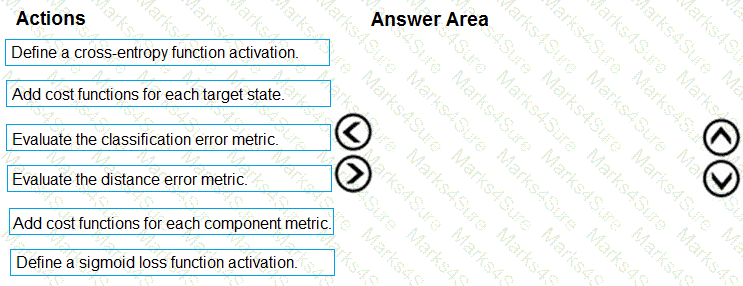
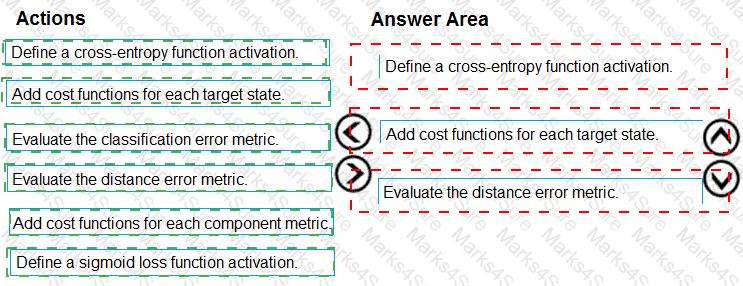

You need to implement a model development strategy to determine a user’s tendency to respond to an ad.
Which technique should you use?
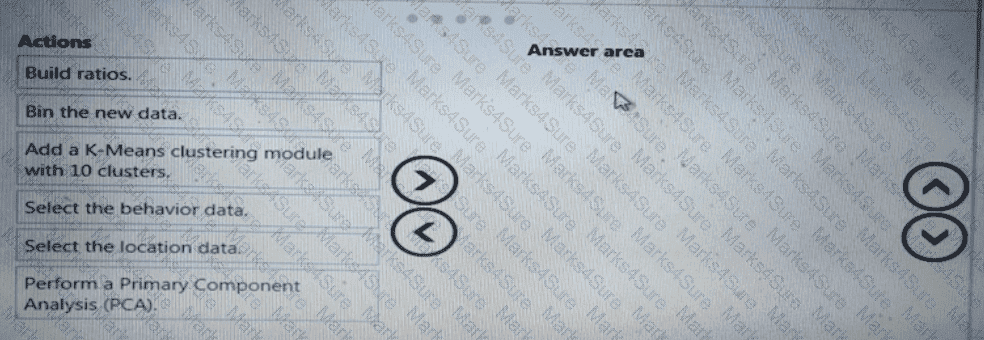
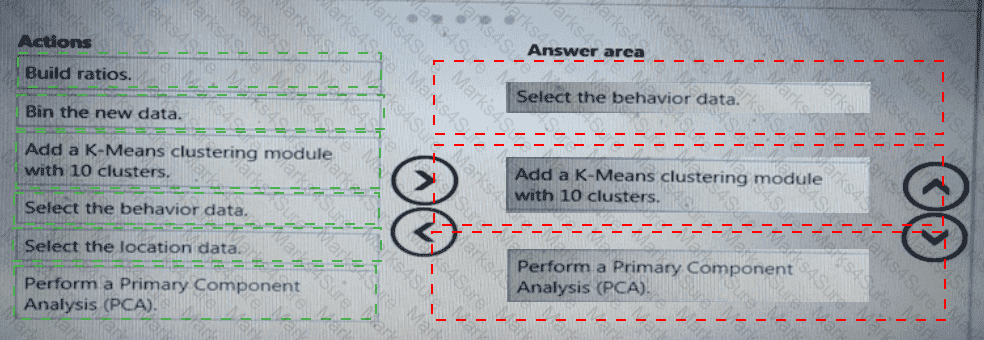
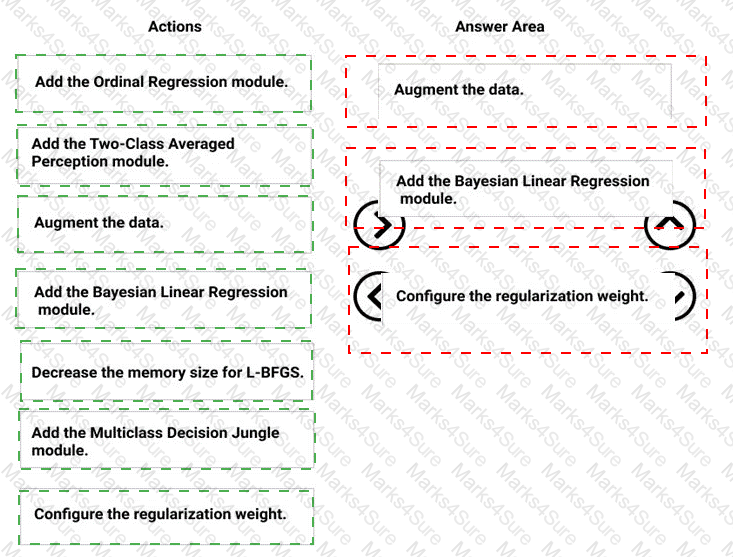
You need to modify the inputs for the global penalty event model to address the bias and variance issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
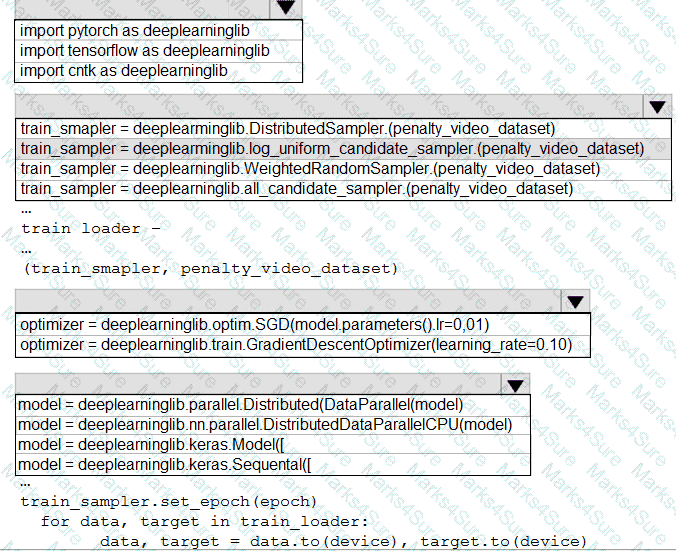
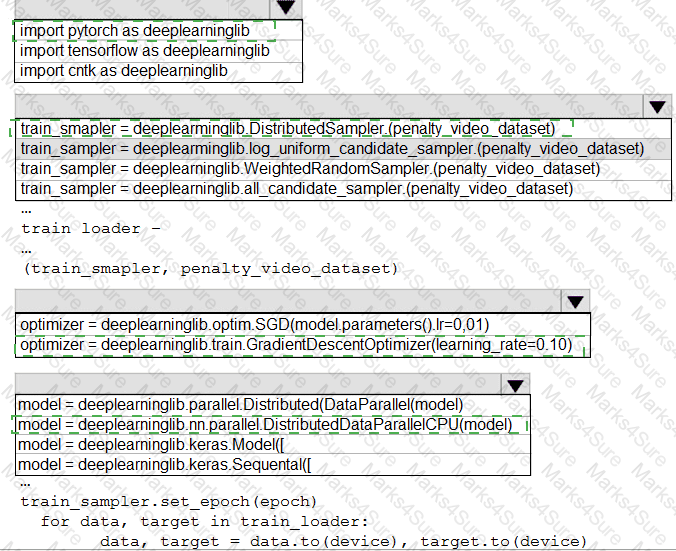
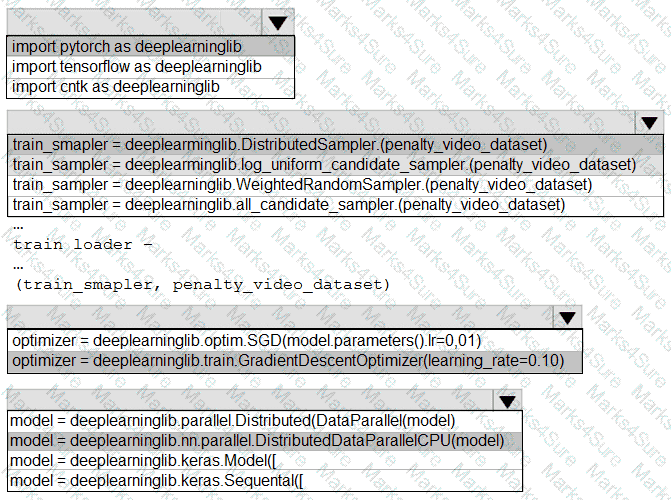
You need to use the Python language to build a sampling strategy for the global penalty detection models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to implement a new cost factor scenario for the ad response models as illustrated in the
performance curve exhibit.
Which technique should you use?

You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
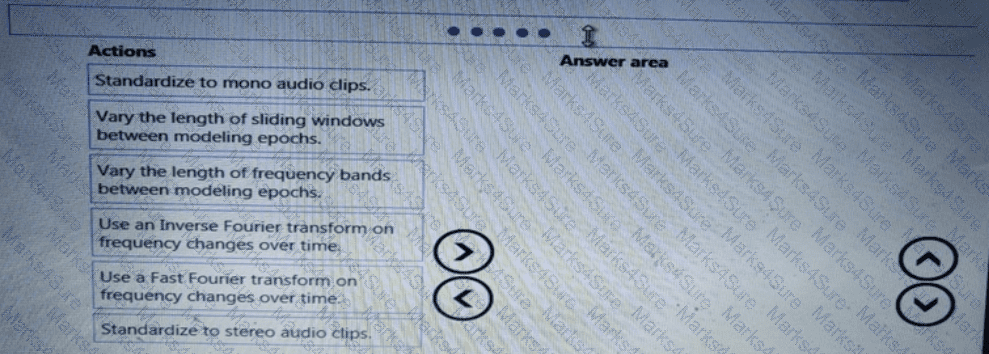
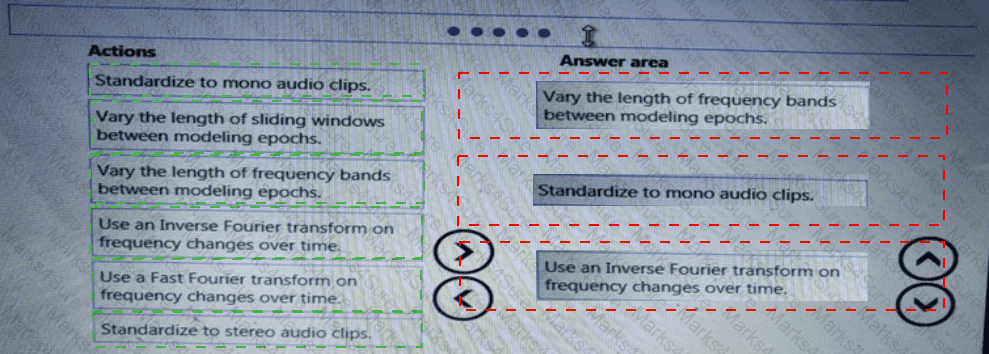
You need to implement a scaling strategy for the local penalty detection data.
Which normalization type should you use?
You need to implement a feature engineering strategy for the crowd sentiment local models.
What should you do?
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
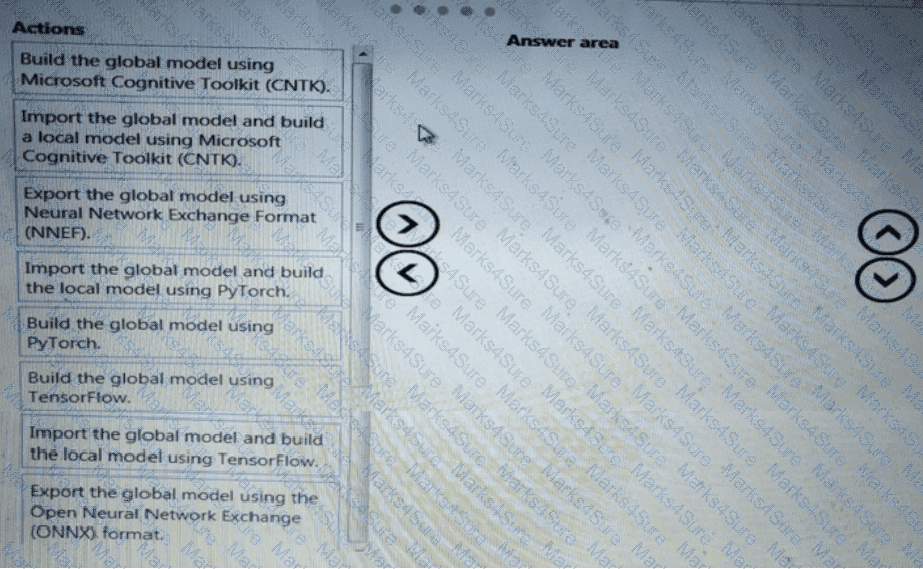
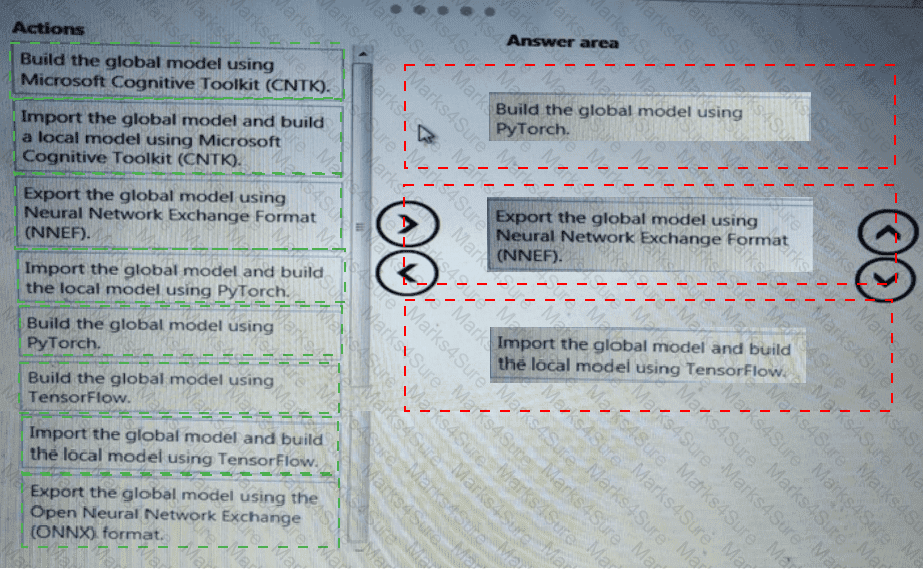
You need to build a feature extraction strategy for the local models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
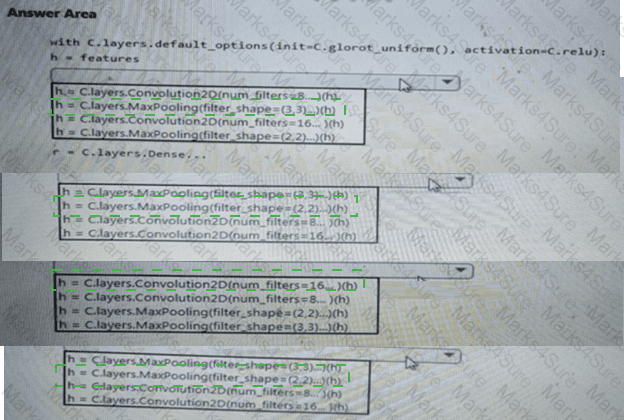
You create a model to forecast weather conditions based on historical data.
You need to create a pipeline that runs a processing script to load data from a datastore and pass the processed data to a machine learning model training script.
Solution: Run the following code:
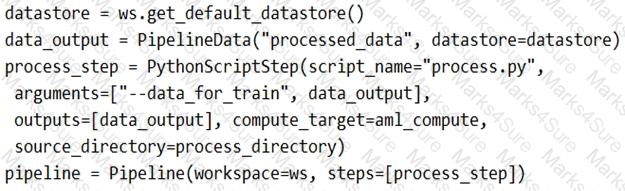
Does the solution meet the goal?
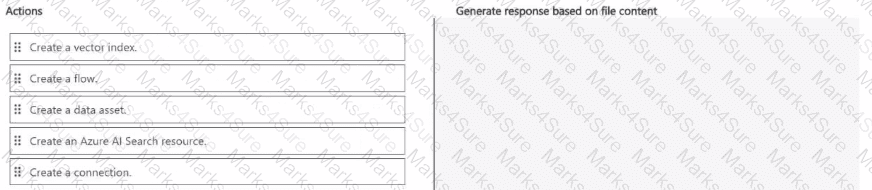
You have an Azure AI Foundry project with a connected Azure OpenAI Service model.
You have a set of text files stored locally on your computer.
You must set up a flow that will generate responses based on the content of your local files.
You need to implement a solution.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You manage an Azure Al Foundry project.
You need to develop a solution that uses an Azure OpenAI Service model designed to support reasoning and problem solving. Which model should you use?
you create an Azure Machine learning workspace named workspace1. The workspace contains a Python SOK v2 notebook mat uses Mallow to correct model coaxing men’s anal arracks from your local computer.
Vou must reuse the notebook to run on Azure Machine I earning compute instance m workspace.
You need to comminute to log training and artifacts from your data science code.
What should you do?
You have a Jupyter Notebook that contains Python code that is used to train a model.
You must create a Python script for the production deployment. The solution must minimize code maintenance.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You create an Azure Databricks workspace and a linked Azure Machine Learning workspace.
You have the following Python code segment in the Azure Machine Learning workspace:
import mlflow
import mlflow.azureml
import azureml.mlflow
import azureml.core
from azureml.core import Workspace
subscription_id = ' subscription_id '
resourse_group = ' resource_group_name '
workspace_name = ' workspace_name '
ws = Workspace.get(name=workspace_name,
subscription_id=subscription_id,
resource_group=resource_group)
experimentName = " /Users/{user_name}/{experiment_folder}/{experiment_name} "
mlflow.set_experiment(experimentName)
uri = ws.get_mlflow_tracking_uri()
mlflow.set_tracking_uri(uri)
Instructions: For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.



You run a script as an experiment in Azure Machine Learning.
You have a Run object named run that references the experiment run. You must review the log files that were generated during the experiment run.
You need to download the log files to a local folder for review.
Which two code segments can you run to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
An IT department creates the following Azure resource groups and resources:

The IT department creates an Azure Kubernetes Service (AKS)-based inference compute target named aks-cluster in the Azure Machine Learning workspace.
You have a Microsoft Surface Book computer with a GPU. Python 3.6 and Visual Studio Code are installed.
You need to run a script that trains a deep neural network (DNN) model and logs the loss and accuracy metrics.
Solution: Attach the mlvm virtual machine as a compute target in the Azure Machine Learning workspace. Install the Azure ML SDK on the Surface Book and run Python code to connect to the workspace. Run the training script as an experiment on the mlvm remote compute resource.
You manage an Azure Machine Learning workspace.
You build an image recognition training pipeline, which includes hyperparameter tuning. For each epoch run, you plan to log the following metrics:
• the transformed images used for training in an existing folder
• a description to explain the hyperparameter changes
You need to configure logging for the experiment.
Which two functions should you use? Each correct answer presents part of the solution. Choose two. NOTE: Each correct selection is worth one point.
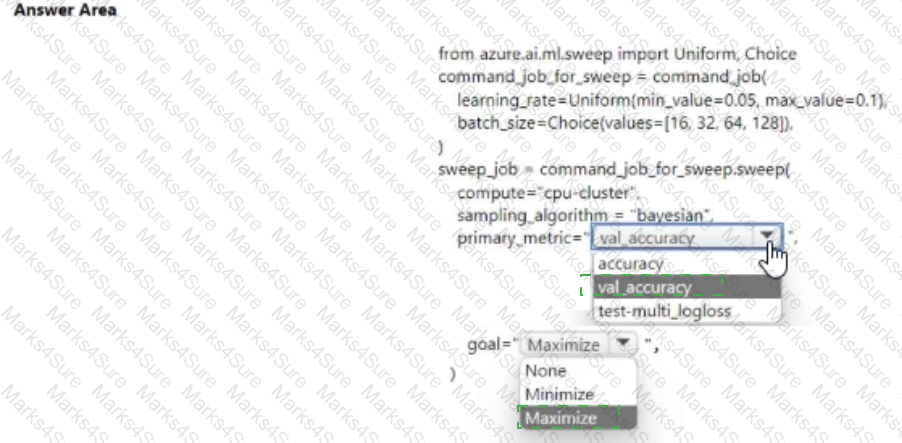
You use Azure Machine Learning to train a machine learning model.
You use the following training script in Python to perform logging:

You must use a Python script to define a sweep job.
You need to provide the primary metric and goal you want hyperparameter tuning to optimize.
NOTE: Each correct selection is worth one point.

You manage an Azure Machine Learning workspace.
You plan to irain a natural language processing (NLP) tew classification model in multiple languages by using Azure Machine learning Python SDK v2. You need to configure the language of the text classification job by using automated machine learning. Which method of the TextClassifkationlob class should you use?
You have an Azure Machine Learning workspace that includes an AmICompute cluster and a batch endpoint. You clone a repository that contains an MLflow model to your local computer. You need to ensure that you can deploy the model to the batch endpoint.
Solution: Add a compute resource to the workspace.
Does the solution meet the goal?
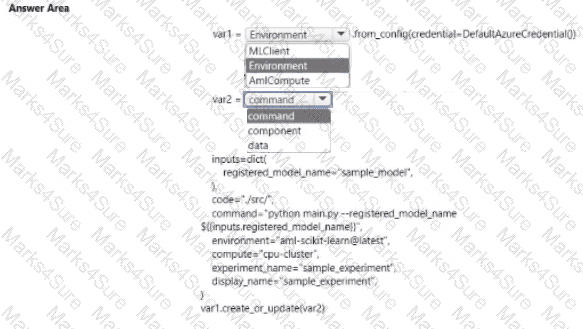
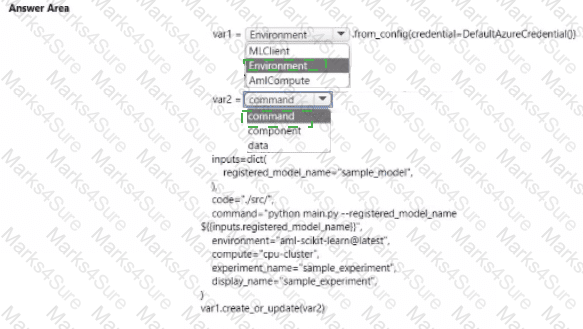
You create an Azure Machine Learning workspace
You are developing a Python SDK v2 notebook to perform custom model training in the workspace. The notebook code imports all required packages.
You need to complete the Python SDK v2 code to include a training script. environment, and compute information.
How should you complete ten code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point
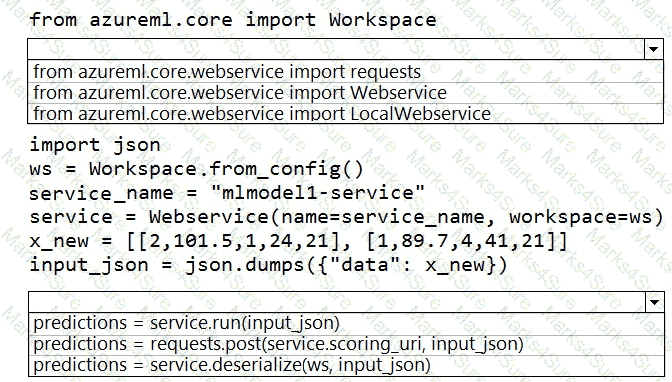
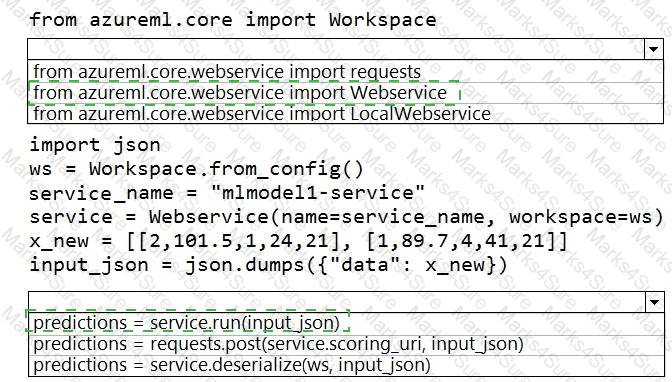
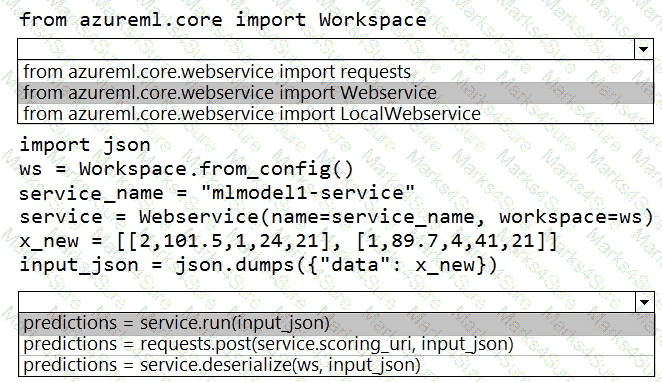
You deploy a model in Azure Container Instance.
You must use the Azure Machine Learning SDK to call the model API.
You need to invoke the deployed model using native SDK classes and methods.
How should you complete the command? To answer, select the appropriate options in the answer areas.
NOTE: Each correct selection is worth one point.
You are using C-Support Vector classification to do a multi-class classification with an unbalanced training dataset. The C-Support Vector classification using Python code shown below:

You need to evaluate the C-Support Vector classification code.
Which evaluation statement should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.



You run an experiment that uses an AutoMLConfig class to define an automated machine learning task with a maximum of ten model training iterations. The task will attempt to find the best performing model based on a metric named accuracy.
You submit the experiment with the following code:
You need to create Python code that returns the best model that is generated by the automated machine learning task. Which code segment should you use?
A)

B)

C)

D)

You train a classification model by using a decision tree algorithm.
You create an estimator by running the following Python code. The variable feature_names is a list of all feature names, and class_names is a list of all class names.
from interpret.ext.blackbox import TabularExplainer

You need to explain the predictions made by the model for all classes by determining the importance of all features.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.



You write five Python scripts that must be processed in the order specified in Exhibit A – which allows the same modules to run in parallel, but will wait for modules with dependencies.
You must create an Azure Machine Learning pipeline using the Python SDK, because you want to script to create the pipeline to be tracked in your version control system. You have created five PythonScriptSteps and have named the variables to match the module names.
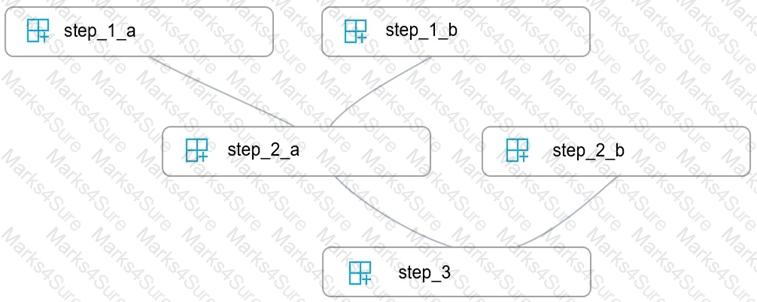
You need to create the pipeline shown. Assume all relevant imports have been done.
Which Python code segment should you use?

You create an Azure Machine Learning workspace. You train an MLflow-formatted regression model by using tabular structured data.
You must use a Responsible Al dashboard to assess the model.
You need to use the Azure Machine Learning studio Ul to generate the Responsible A dashboard.
What should you do first?
You are performing clustering by using the K-means algorithm.
You need to define the possible termination conditions.
Which three conditions can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
You create a multi-class image classification deep learning model.
You train the model by using PyTorch version 1.2.
You need to ensure that the correct version of PyTorch can be identified for the inferencing environment when the model is deployed.
What should you do?
You define a datastore named ml-data for an Azure Storage blob container. In the container, you have a folder named train that contains a file named data.csv. You plan to use the file to train a model by using the Azure Machine Learning SDK.
You plan to train the model by using the Azure Machine Learning SDK to run an experiment on local compute.
You define a DataReference object by running the following code:
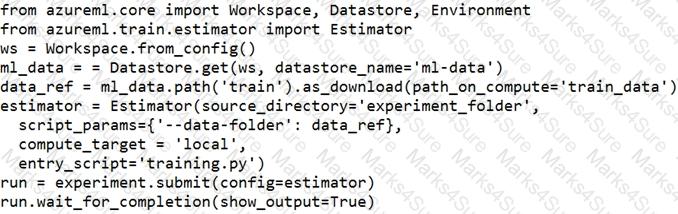
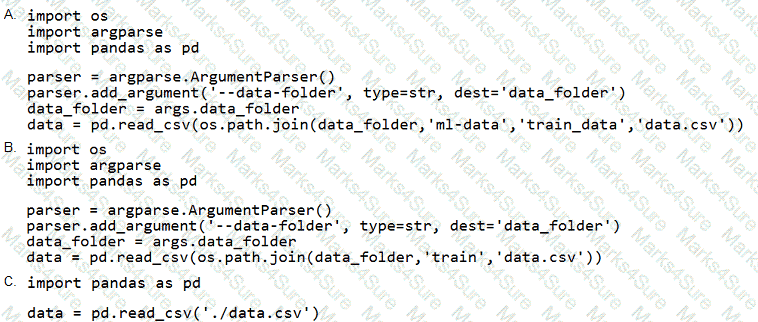
You need to load the training data.
Which code segment should you use?

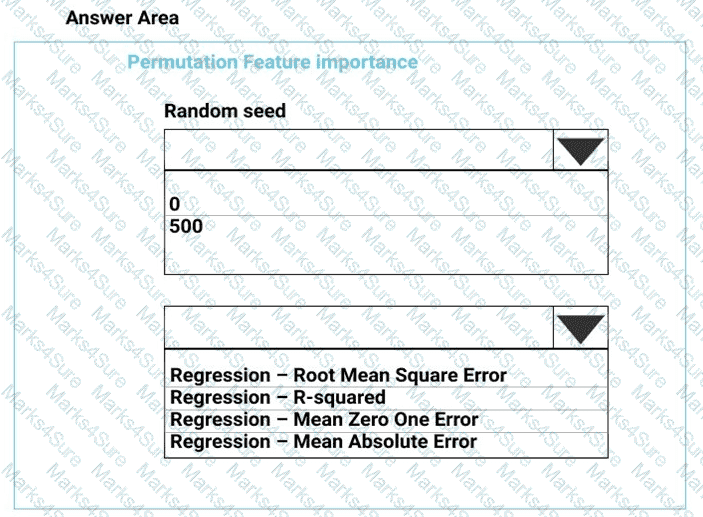
You need to configure the Permutation Feature Importance module for the model training requirements.
What should you do? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
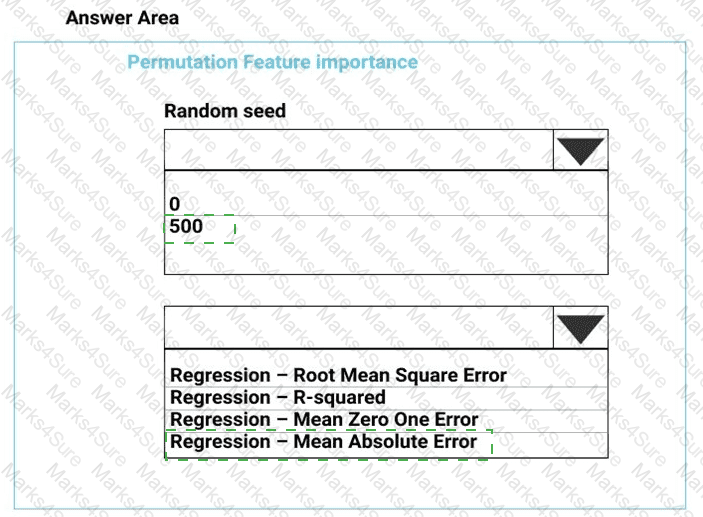

You need to set up the Permutation Feature Importance module according to the model training requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
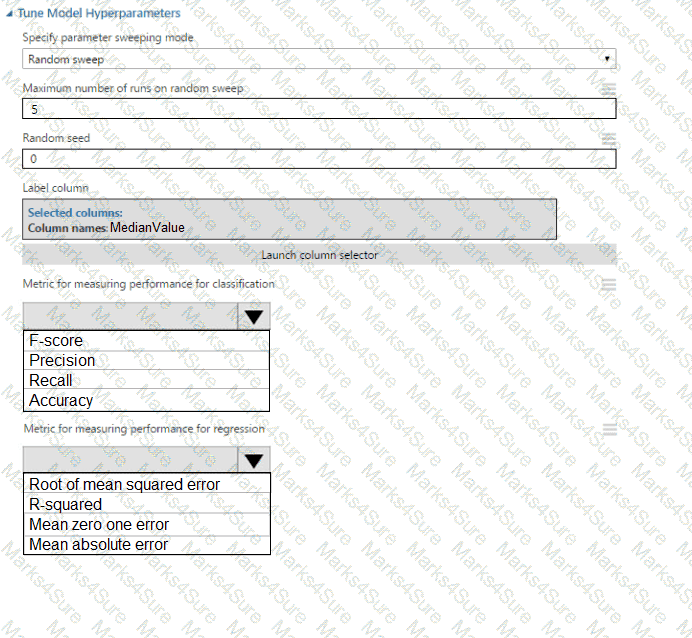
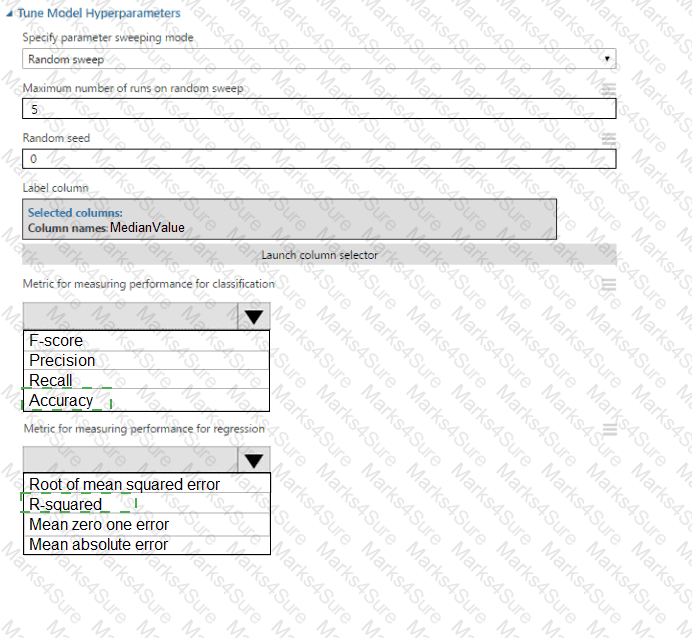
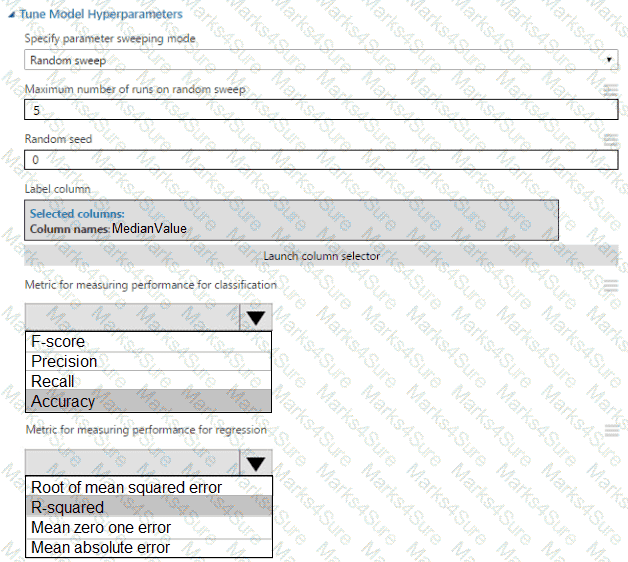
You need to correct the model fit issue.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
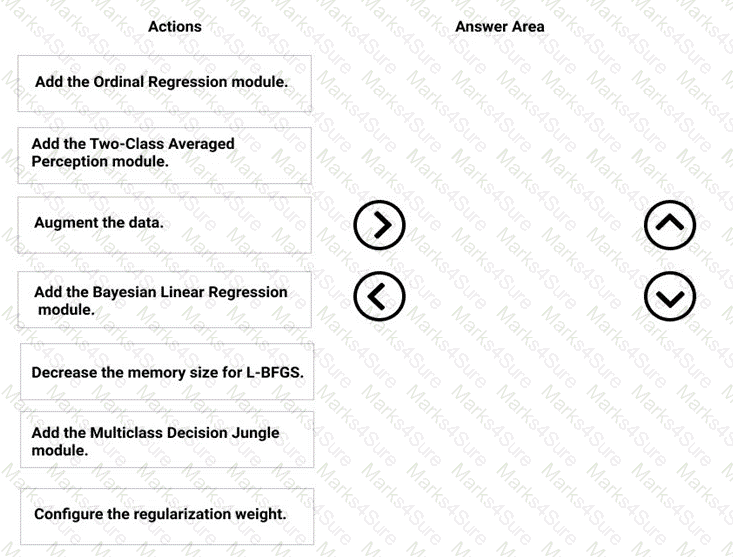

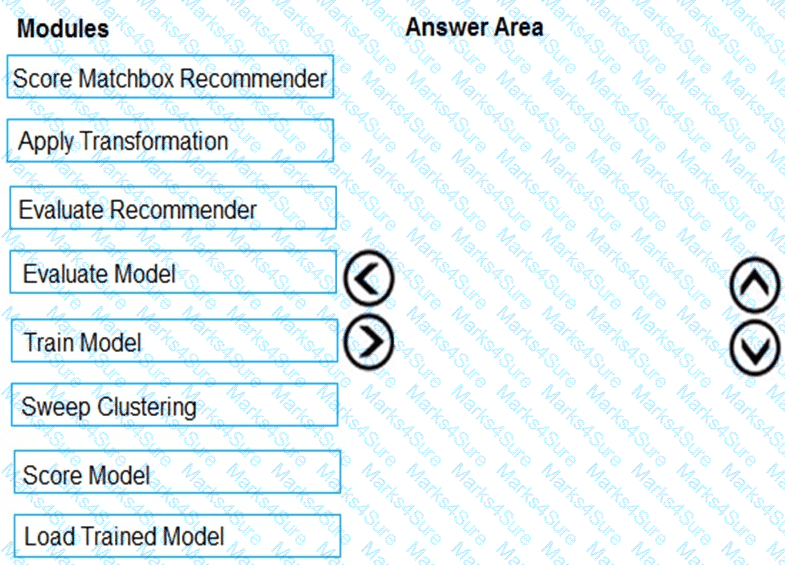
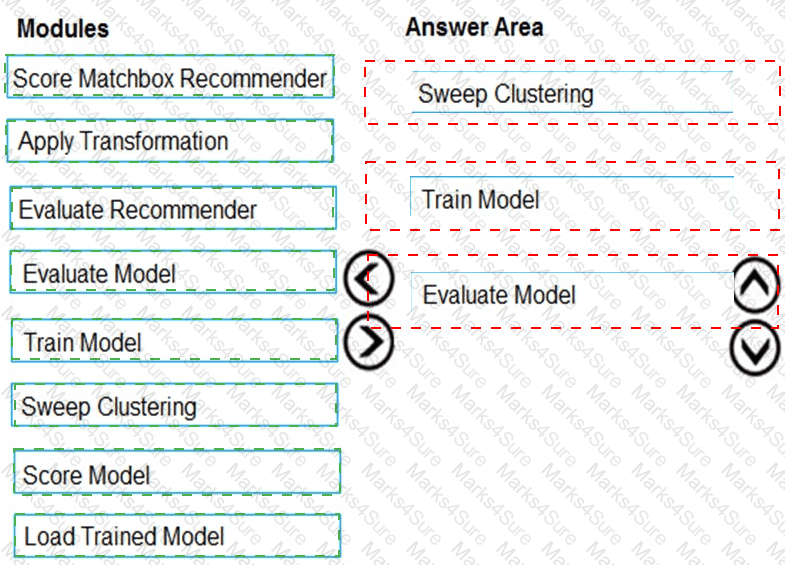
You need to produce a visualization for the diagnostic test evaluation according to the data visualization requirements.
Which three modules should you recommend be used in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.

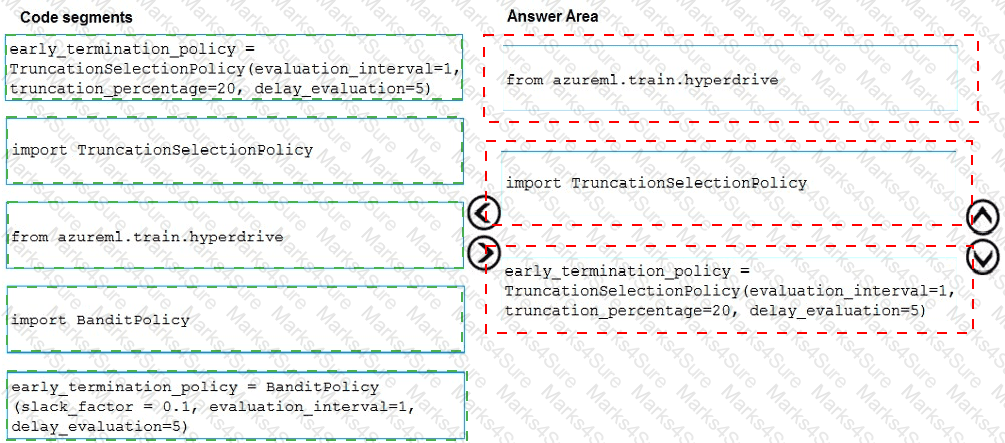
You need to implement early stopping criteria as suited in the model training requirements.
Which three code segments should you use to develop the solution? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.


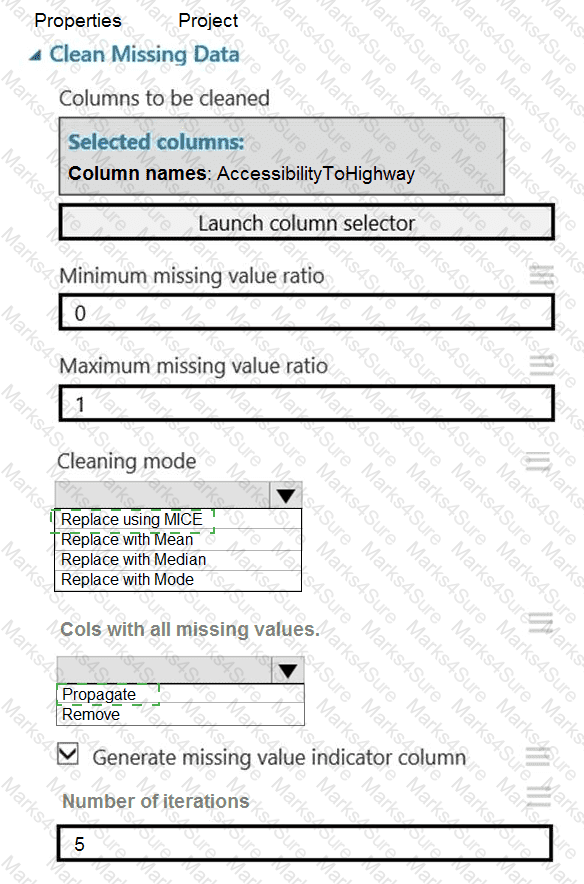
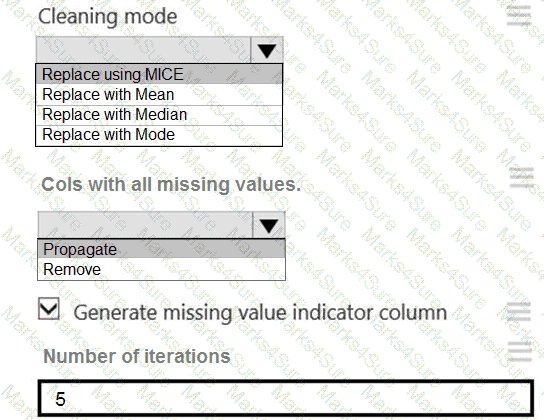
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

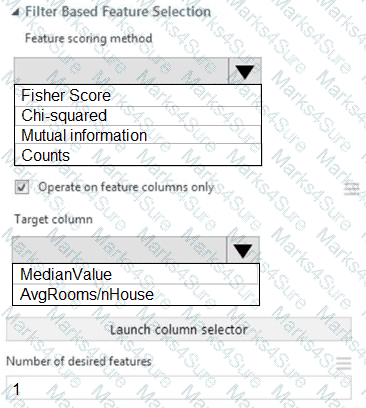
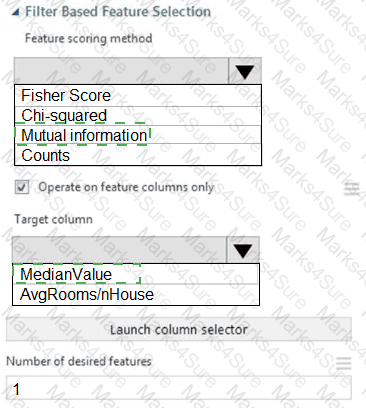
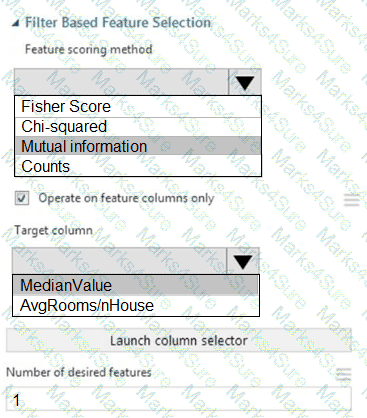
You need to configure the Feature Based Feature Selection module based on the experiment requirements and datasets.
How should you configure the module properties? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
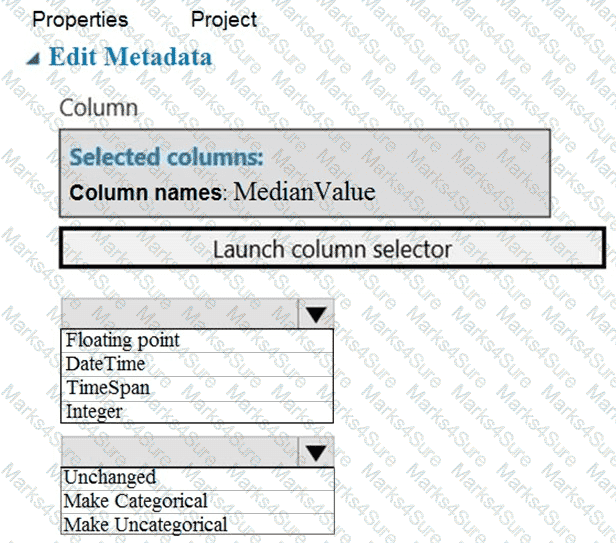
You need to configure the Edit Metadata module so that the structure of the datasets match.
Which configuration options should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
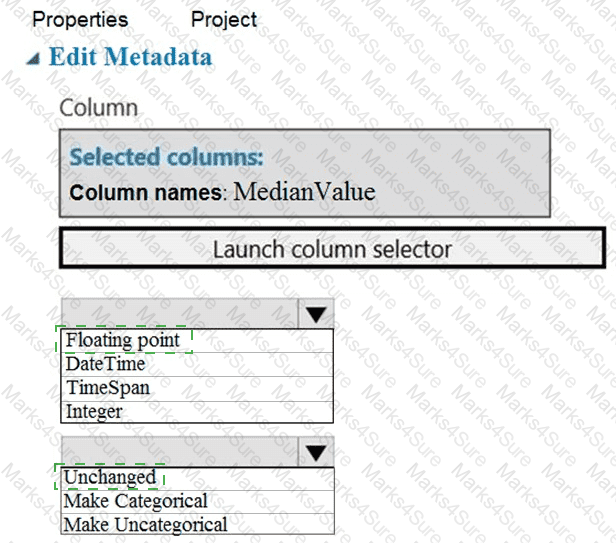
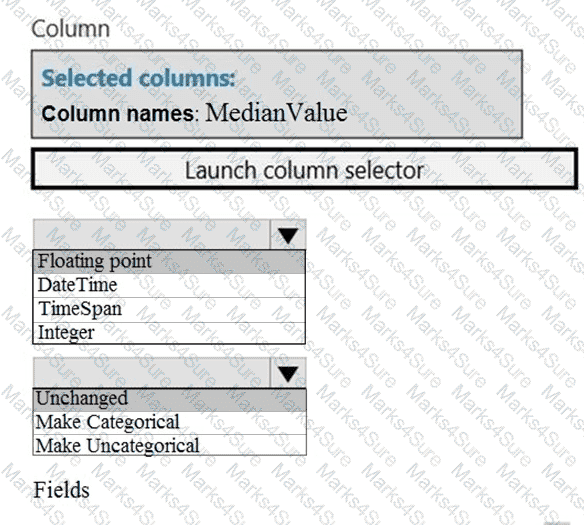
You need to identify the methods for dividing the data according, to the testing requirements.
Which properties should you select? To answer, select the appropriate option-, m the answer area. NOTE: Each correct selection is worth one point.
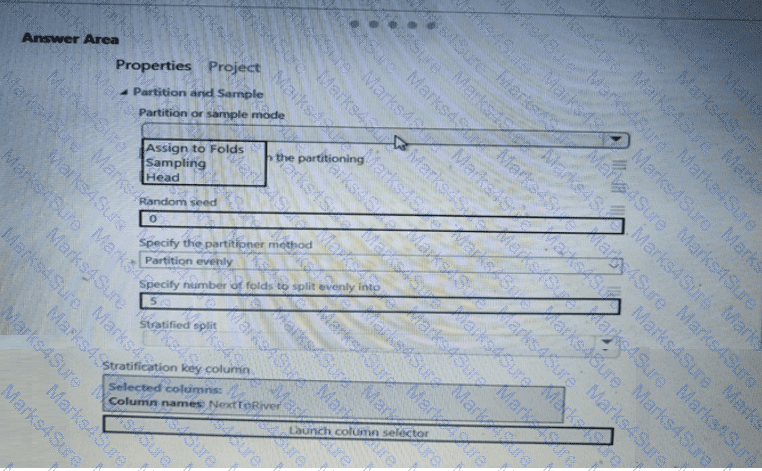
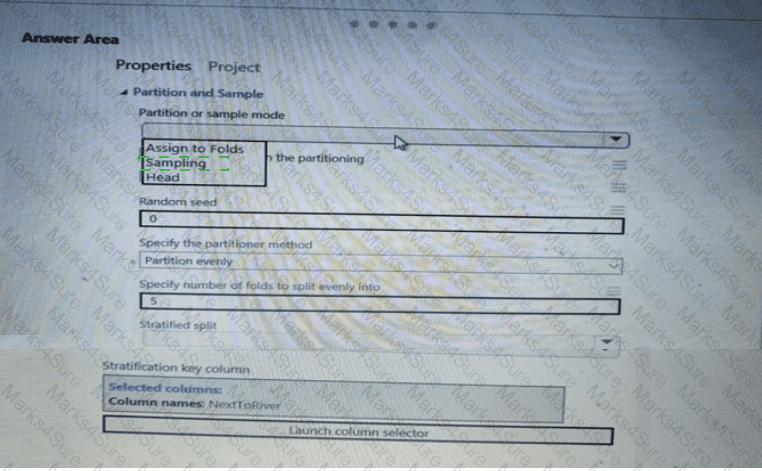
You need to identify the methods for dividing the data according to the testing requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.



You need to visually identify whether outliers exist in the Age column and quantify the outliers before the outliers are removed.
Which three Azure Machine Learning Studio modules should you use in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.