Free Practice Questions for the CompTIA Data+ DY0-001 Exam (2026 Updated)
At Marks4sure, we are dedicated to providing IT professionals with the most accurate and reliable preparation materials for the CompTIA DY0-001 exam. To support your certification journey, we have made a selection of our premium 2026 CompTIA Data+ practice questions and answers available completely free. You can take this practice test as many times as you need. Every question includes a detailed, expertly verified explanation to ensure you fully grasp the core security concepts before test day.
A data scientist is working with a data set that covers a two-year period for a large number of machines. The data set contains:
Machine system ID numbers
Sensor measurement values
Daily timestamps for each machine
The data scientist needs to plot the total measurements from all the machines over the entire time period. Which of the following is the best way to present this data?
A data scientist is analyzing a data set with categorical features and would like to make those features more useful when building a model. Which of the following data transformation techniques should the data scientist use? (Choose two.)
Which of the following modeling tools is appropriate for solving a scheduling problem?
A data scientist receives an update on a business case about a machine that has thousands of error codes. The data scientist creates the following summary statistics profile while reviewing the logs for each machine:
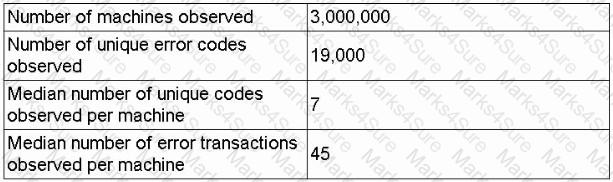
| Number of machines observed | 3,000,000
| Number of unique error codes observed | 19,000
| Median number of unique codes per machine | 7
| Median number of error transactions | 45
Which of the following is the most likely concern with respect to data design for model ingestion?
A computer vision model is trained to identify cats on a training set that is composed of both cat and dog images. The model predicts a picture of a cat is a dog. Which of the following describes this error?
Which of the following issues should a data scientist be most concerned about when generating a synthetic data set?
Which of the following best describes the minimization of the residual term in a ridge linear regression?
Which of the following distance metrics for KNN is best described as a straight line?
Under perfect conditions, E. coli bacteria would cover the entire earth in a matter of days. Which of the following types of models is the best for explaining this type of growth?
A data scientist is standardizing a large data set that contains website addresses. A specific string inside some of the web addresses needs to be extracted. Which of the following is the best method for extracting the desired string from the text data?
A data analyst wants to use compression on an analyzed data set and send it to a new destination for further processing. Which of the following issues will most likely occur?
A data scientist is merging two tables. Table 1 contains employee IDs and roles. Table 2 contains employee IDs and team assignments. Which of the following is the best technique to combine these data sets?
An analyst wants to show how the component pieces of a company ' s business units contribute to the company ' s overall revenue. Which of the following should the analyst use to best demonstrate this breakdown?
A data scientist uses a large data set to build multiple linear regression models to predict the likely market value of a real estate property. The selected new model has an RMSE of 995 on the holdout set and an adjusted R² of 0.75. The benchmark model has an RMSE of 1,000 on the holdout set. Which of the following is the best business statement regarding the new model?





A data scientist is using the following confusion matrix to assess model performance:
Actually Fails
Actually Succeeds
Predicted to Fail
80%
20%
Predicted to Succeed
15%
85%

The model is predicting whether a delivery truck will be able to make 200 scheduled delivery stops.
Every time the model is correct, the company saves 1 hour in planning and scheduling.
Every time the model is wrong, the company loses 4 hours of delivery time.
Which of the following is the net model impact for the company?
A data scientist would like to model a complex phenomenon using a large data set composed of categorical, discrete, and continuous variables. After completing exploratory data analysis, the data scientist is reasonably certain that no linear relationship exists between the predictors and the target. Although the phenomenon is complex, the data scientist still wants to maintain the highest possible degree of interpretability in the final model. Which of the following algorithms best meets this objective?
A data scientist is deploying a model that needs to be accessed by multiple departments with minimal development effort by the departments. Which of the following APIs would be best for the data scientist to use?
A data scientist has built a model that provides the likelihood of an error occurring in a factory. The historical accuracy of the model is 90%. At a specific factory, the model is reporting a likelihood score of 0.90. Which of the following explains a confidence score of 0.90?
A data scientist needs to analyze a company ' s chemical businesses and is using the master database of the conglomerate company. Nothing in the data differentiates the data observations for the different businesses. Which of the following is the most efficient way to identify the chemical businesses ' observations?
A company created a very popular collectible card set. Collectors attempt to collect the entire set, but the availability of each card varies, because some cards have higher production volumes than others. The set contains a total of 12 cards. The attributes of the cards are shown.
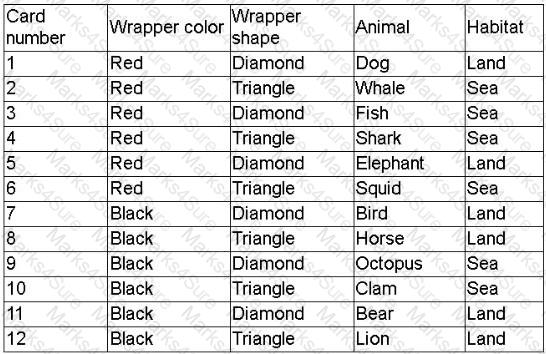
The data scientist is tasked with designing an initial model iteration to predict whether the animal on the card lives in the sea or on land, given the card ' s features: Wrapper color, Wrapper shape, and Animal.
Which of the following is the best way to accomplish this task?
PDF + Testing Engine

Testing Engine
PDF (Q&A)
